Small Language Models Benchmarking
All we know about Small LLMs
#Citation
Title: SLM-Bench: A Comprehensive Benchmark of Small Language Models on Environmental Impacts.
Abstract: Small Language Models (SLMs) offer computational efficiency and accessibility, yet a systematic evaluation of their performance and environmental impact remains lacking. We introduce SLM-Bench, the first benchmark specifically designed to assess SLMs across multiple dimensions, including accuracy, computational efficiency, and sustainability metrics. SLM-Bench evaluates 15 SLMs on 9 NLP tasks using 23 datasets spanning 14 domains, providing a rigorous comparison of their effectiveness. Unlike prior benchmarks, SLM-Bench quantifies 11 metrics across correctness, computation, and consumption, enabling a holistic assessment of efficiency trade-offs. Our evaluation considers controlled hardware conditions, ensuring fair comparisons across models. We develop an open-source benchmarking pipeline with standardized evaluation protocols to facilitate reproducibility and further research. Our findings highlight the diverse trade-offs among SLMs, where some models excel in accuracy while others achieve superior energy efficiency. SLM-Bench sets a new standard for SLM evaluation, bridging the gap between resource efficiency and real-world applicability.
Github: https://anonymous.4open.science/r/slm-bench-experiments-87F6
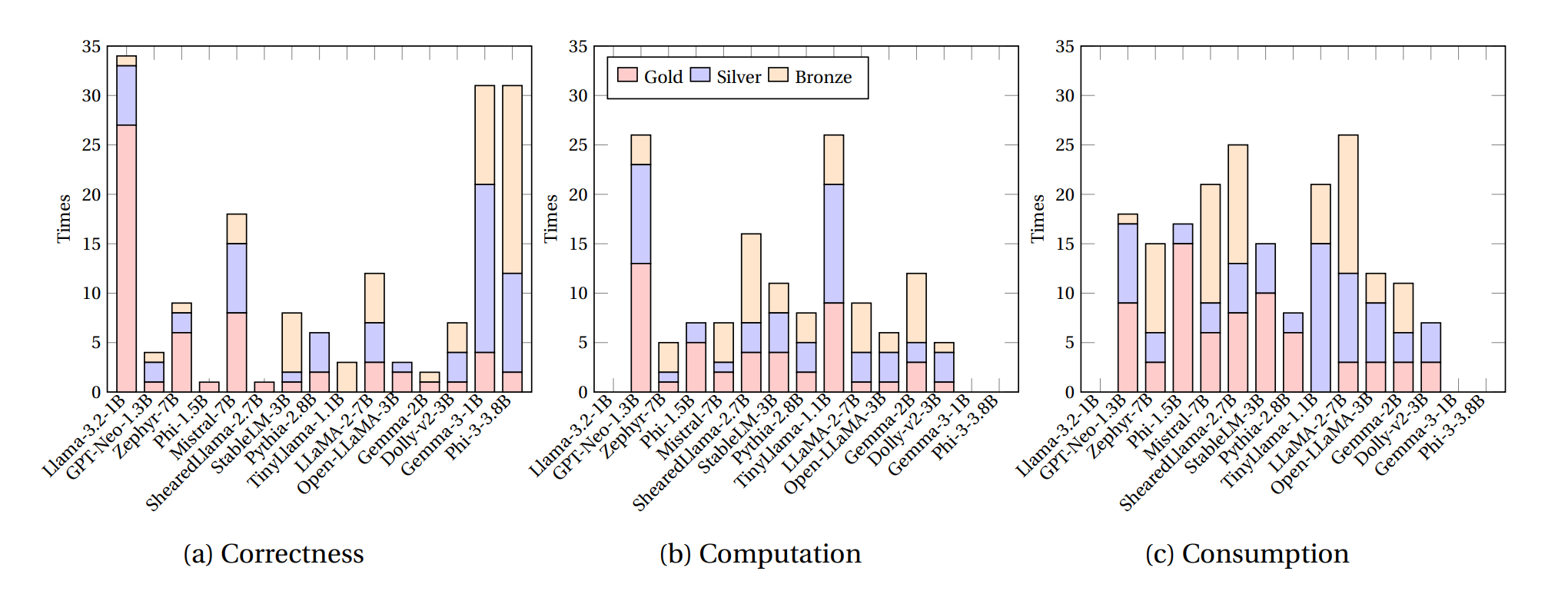
Model Performance Scoreboard
ℹ️Medal Distribution
- 🥇Gold Medal: Outstanding performance across metrics
- 🥈Silver Medal: Strong performance with good balance
- 🥉Bronze Medal: Solid baseline performance
ℹ️GPU - L4
| Model | Provider | Parameters | Context Window | Training Time | Gold Medals | Silver Medals | Bronze Medals |
|---|---|---|---|---|---|---|---|
Llama-3.2-1B | Meta | 1.24B | 128000 | Unknown | 🥇80 | 🥈65 | 🥉50 |
GPT-Neo-1.3B | EleutherAI | 1.37B | 2048 | 10 days (32 GPUs) | 🥇75 | 🥈60 | 🥉45 |
Zephyr-7B | Hugging Face | 7.00B | 8192 | 20 days (64 GPUs) | 🥇70 | 🥈55 | 🥉40 |
Phi-1.5 | Microsoft | 2.70B | 2048 | 12 days (32 GPUs) | 🥇65 | 🥈50 | 🥉35 |
Mistral-7B | Mistral AI | 7.00B | 8192 | 15 days (128 GPUs) | 🥇60 | 🥈45 | 🥉30 |
ShearedLlama-2.7B | Hugging Face | 2.70B | 2048 | 12 days (32 GPUs) | 🥇55 | 🥈40 | 🥉25 |
StableLM-3B | Stability AI | 3.00B | 2048 | 14 days (64 GPUs) | 🥇50 | 🥈35 | 🥉20 |
Pythia-2.8B | EleutherAI | 2.80B | 2048 | 12 days (32 GPUs) | 🥇45 | 🥈30 | 🥉15 |
TinyLlama-1.1B | Hugging Face | 1.10B | 2048 | 8 days (16 GPUs) | 🥇40 | 🥈25 | 🥉10 |
LLaMA-2-7B | Meta | 6.47B | 4096 | 21 days (64 GPUs) | 🥇35 | 🥈20 | 🥉5 |
Open-LLaMA-3B | OpenLM | 3.00B | 4096 | 18 days (64 GPUs) | 🥇30 | 🥈15 | 🥉0 |
Gemma-2B | 2.00B | 2048 | 14 days (32 GPUs) | 🥇25 | 🥈10 | 🥉0 | |
Dolly-v2-3B | DataBricks | 3.00B | 2048 | 10 days (32 GPUs) | 🥇20 | 🥈5 | 🥉0 |
Gemma-3-1B | 1.00B | 32000 | 30 days (512 GPUs | 🥇15 | 🥈0 | 🥉0 | |
Phi-3 | Microsoft | 3.82B | 128000 | 7 days (512 GPUs) | 🥇10 | 🥈0 | 🥉0 |
ℹ️GPU - A10G
| Model | Provider | Parameters | Context Window | Training Time | Gold Medals | Silver Medals | Bronze Medals |
|---|---|---|---|---|---|---|---|
Llama-3.2-1B | Meta | 1.24B | 128000 | Unknown | 🥇80 | 🥈65 | 🥉50 |
GPT-Neo-1.3B | EleutherAI | 1.37B | 2048 | 10 days (32 GPUs) | 🥇75 | 🥈60 | 🥉45 |
Zephyr-7B | Hugging Face | 7.00B | 8192 | 20 days (64 GPUs) | 🥇70 | 🥈55 | 🥉40 |
Phi-1.5 | Microsoft | 2.70B | 2048 | 12 days (32 GPUs) | 🥇65 | 🥈50 | 🥉35 |
Mistral-7B | Mistral AI | 7.00B | 8192 | 15 days (128 GPUs) | 🥇60 | 🥈45 | 🥉30 |
ShearedLlama-2.7B | Hugging Face | 2.70B | 2048 | 12 days (32 GPUs) | 🥇55 | 🥈40 | 🥉25 |
StableLM-3B | Stability AI | 3.00B | 2048 | 14 days (64 GPUs) | 🥇50 | 🥈35 | 🥉20 |
Pythia-2.8B | EleutherAI | 2.80B | 2048 | 12 days (32 GPUs) | 🥇45 | 🥈30 | 🥉15 |
TinyLlama-1.1B | Hugging Face | 1.10B | 2048 | 8 days (16 GPUs) | 🥇40 | 🥈25 | 🥉10 |
LLaMA-2-7B | Meta | 6.47B | 4096 | 21 days (64 GPUs) | 🥇35 | 🥈20 | 🥉5 |
Open-LLaMA-3B | OpenLM | 3.00B | 4096 | 18 days (64 GPUs) | 🥇30 | 🥈15 | 🥉0 |
Gemma-2B | 2.00B | 2048 | 14 days (32 GPUs) | 🥇25 | 🥈10 | 🥉0 | |
Dolly-v2-3B | DataBricks | 3.00B | 2048 | 10 days (32 GPUs) | 🥇20 | 🥈5 | 🥉0 |
Gemma-3-1B | 1.00B | 32000 | 30 days (512 GPUs | 🥇15 | 🥈0 | 🥉0 | |
Phi-3 | Microsoft | 3.82B | 128000 | 7 days (512 GPUs) | 🥇10 | 🥈0 | 🥉0 |
Our Proposed & Results
Overview of SLMs
Small Language Models (SLMs) have gained significant traction in both research and industry, with continuous advancements in recent years. Since the release of GPT-Neo-1.3B in 2021, the field has witnessed a steady stream of new models, each contributing to the expanding capabilities of lightweight AI systems.
By late 2022 and throughout 2023, notable models such as Dolly-v2, Pythia, LLaMA-2, TinyLlama, and Mistral emerged, demonstrating substantial improvements in performance and efficiency. This momentum continued with the introduction of models like Zephyr, ShearedLLaMA, Gemma, and Phi, reflecting growing competitiveness in the SLM landscape.
More recently, the evolution of SLMs has accelerated with the release of Open-LLaMA-3B, LLaMA-3-8B, Gemma-3-1B, and Phi-3-3.8B between mid-2024 and early 2025. These new models mark a significant step forward in the development of compact yet powerful language models. As innovation continues, SLMs are expected to play an increasingly vital role in AI research and real-world applications.

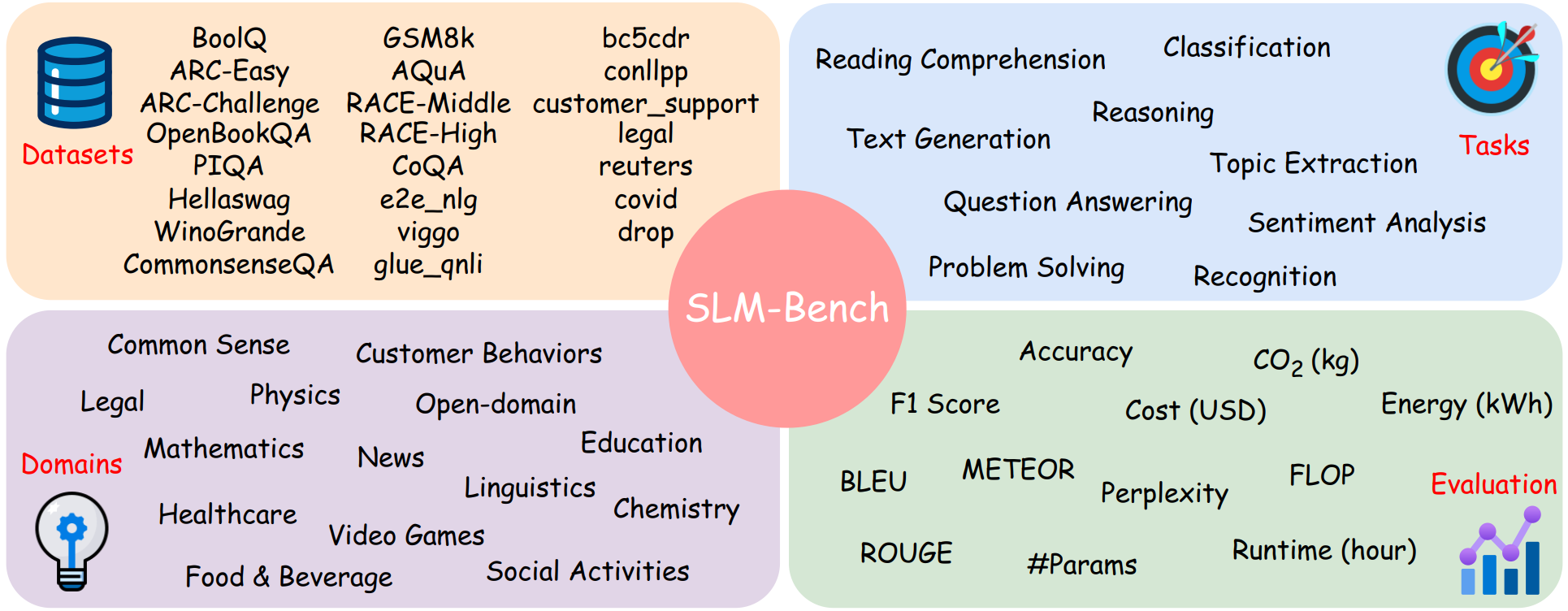
Evaluation of SLM-Bench and Its Impact on SLM Development
SLM-Bench provides a comprehensive evaluation framework for Small Language Models (SLMs), assessing performance across diverse datasets, tasks, and domains. It ensures rigorous testing in areas like reasoning, classification, and text generation while covering fields such as healthcare, mathematics, and linguistics. Beyond accuracy, it evaluates efficiency through energy consumption, CO₂ emissions, and computational costs, promoting sustainable AI development. This holistic approach helps optimize SLMs for real-world applications while maintaining responsible AI deployment. As SLMs evolve, benchmarks like SLM-Bench will be essential in driving innovation and efficiency.
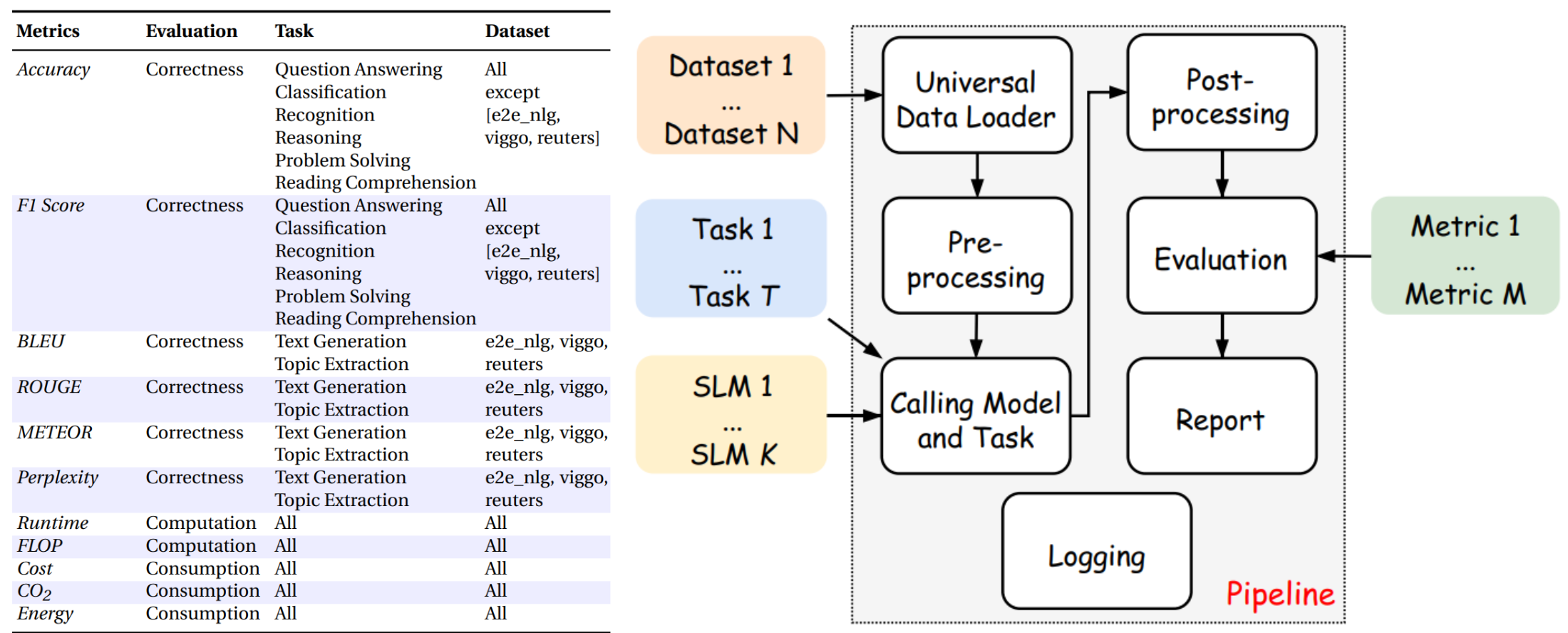
A Comprehensive Pipeline for Evaluating Small Language Models
SLM-Bench employs a structured evaluation pipeline to assess Small Language Models (SLMs) across multiple tasks, datasets, and performance metrics. It measures correctness through accuracy, F1 score, BLEU, ROUGE, and METEOR, while also considering efficiency factors like runtime, energy consumption, and computational cost. The process involves data loading, preprocessing, model execution, and post-processing, followed by evaluation and reporting. By integrating both correctness and efficiency metrics, SLM-Bench ensures a comprehensive assessment of SLM capabilities. This framework is crucial for optimizing models for real-world applications while promoting sustainable AI development.
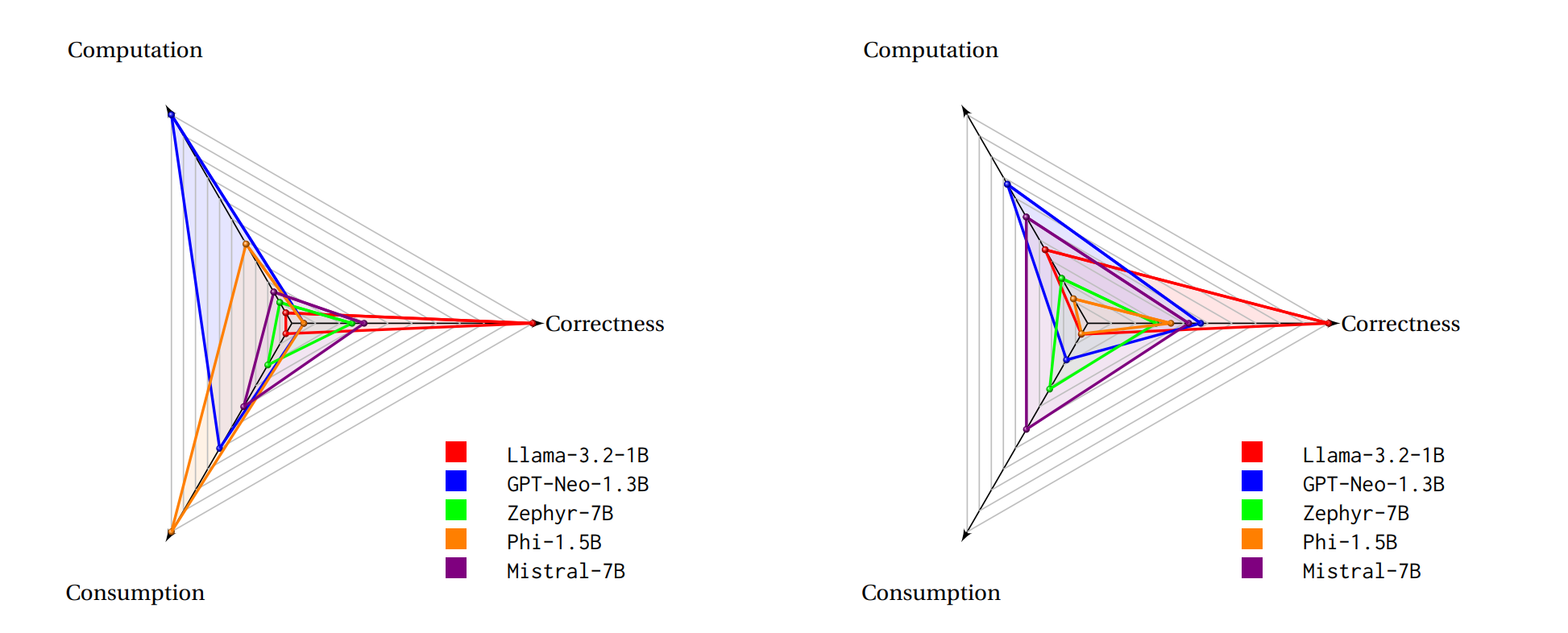
Performance Comparison of Small Language Models
The radar charts visualize the correctness of different Small Language Models (SLMs), highlighting their strengths and weaknesses across various dimensions. Zephyr-7B and Mistral-7B demonstrate superior correctness, outperforming other models, while GPT-Neo-1.3B exhibits strong performance in certain aspects but lags in overall correctness. ShearedLlama-2.7B and Phi-1.5B show competitive results but remain behind leading models. These comparisons provide valuable insights into model efficiency, guiding further improvements in SLM development.